
{kind=link}
AnythingLLM, eine Open-Source-Desktop-Anwendung, ermöglicht das Ausführen von Large Language Models (LLMs), Retrieval-Augmented Generation (RAG)-Systemen und agentenbasierten Tools direkt auf dem heimischen Rechner – ganz ohne Cloud-Zugriff oder komplexe Einrichtung. NVidia hat hier zu einige Optimierungen vorgenommen, wie sie auf ihrem Blog berichten.
Lokale LLM-Ausführung wird zugänglicher
Die One-Click-Installation und das übersichtliche User Interface von AnythingLLM senken die Einstiegshürden für Entwickler und Enthusiasten. Modelle wie Llama und DeepSeek R1 lassen sich ohne zusätzliche Konfiguration nutzen, während RAG-Workflows das Durchsuchen und Auswerten persönlicher Dokumente (PDFs, Word-Dateien, Code-Repositories) im direkten lokalen Kontext erlauben.
Beschleunigung durch RTX GPUs und Tensor Cores
Dank der Optimierung für NVIDIA GeForce RTX und RTX PRO Grafikkarten profitiert AnythingLLM von hardwareseitiger Beschleunigung durch Tensor Cores und den Ollama + Llama.cpp + GGML-Stack. Auf einer GeForce RTX 5090 erzielt die LLM-Inferenz eine 2,4-fach höhere Geschwindigkeit im Vergleich zu Apples M3 Ultra.
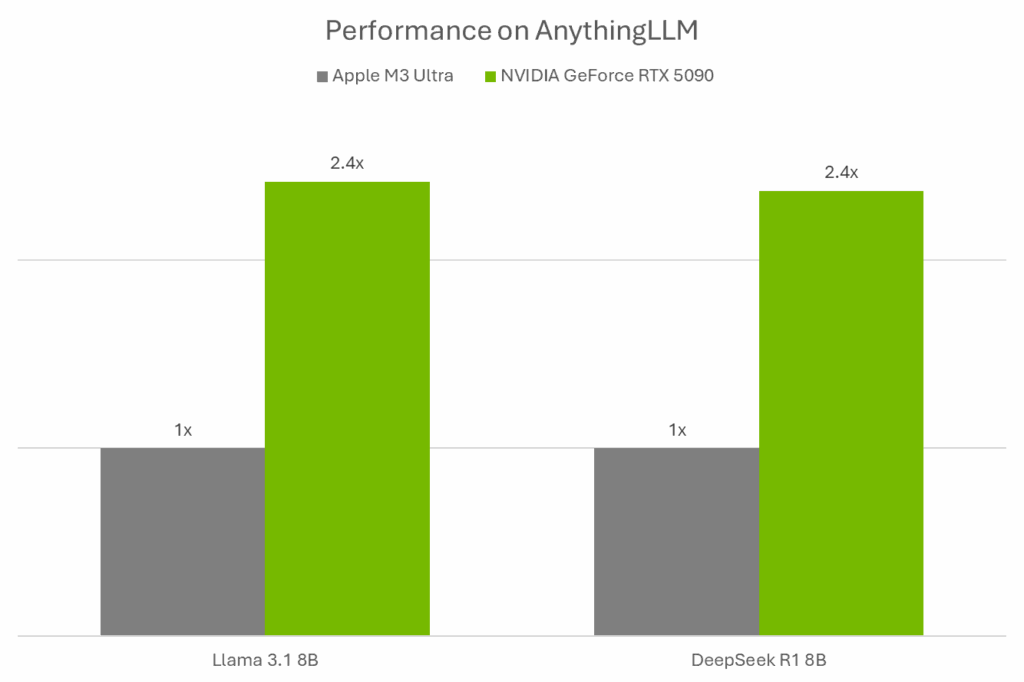
Integration von NVIDIA NIM Microservices
Mit der jüngsten Unterstützung für NVIDIA NIMs (NVIDIA Inference Microservices) können vorgefertigte, auf RTX-GPUs optimierte Modelle per Plug-and-Play genutzt werden. Die manuelle Zusammenstellung von Modelldateien und Endpunktverknüpfungen entfällt. NIMs lassen sich sowohl lokal als auch in der Cloud einsetzen, wodurch Prototyping und späterer Rollout nahtlos ineinandergreifen.
Multimodale Workflows und AI Blueprints
AnythingLLM kann zusammen mit NVIDIAs wachsender Bibliothek an AI Blueprints verwendet werden, um multimodale Anwendungen von Chatbots über Datenanalyse bis zu agentenbasierter Automatisierung zu entwickeln. Die Kombination aus NIM-Support und Blueprints fördert schnelle Iterationen und Prototyping direkt auf RTX-betriebenen Systemen.